mirror of https://github.com/actions/toolkit
54 lines
3.9 KiB
Markdown
54 lines
3.9 KiB
Markdown
# Implementation Details
|
|
|
|
Warning: Implementation details may change at any time without notice. This is meant to serve as a reference to help users understand the package.
|
|
|
|
## Upload/Compression flow
|
|
|
|
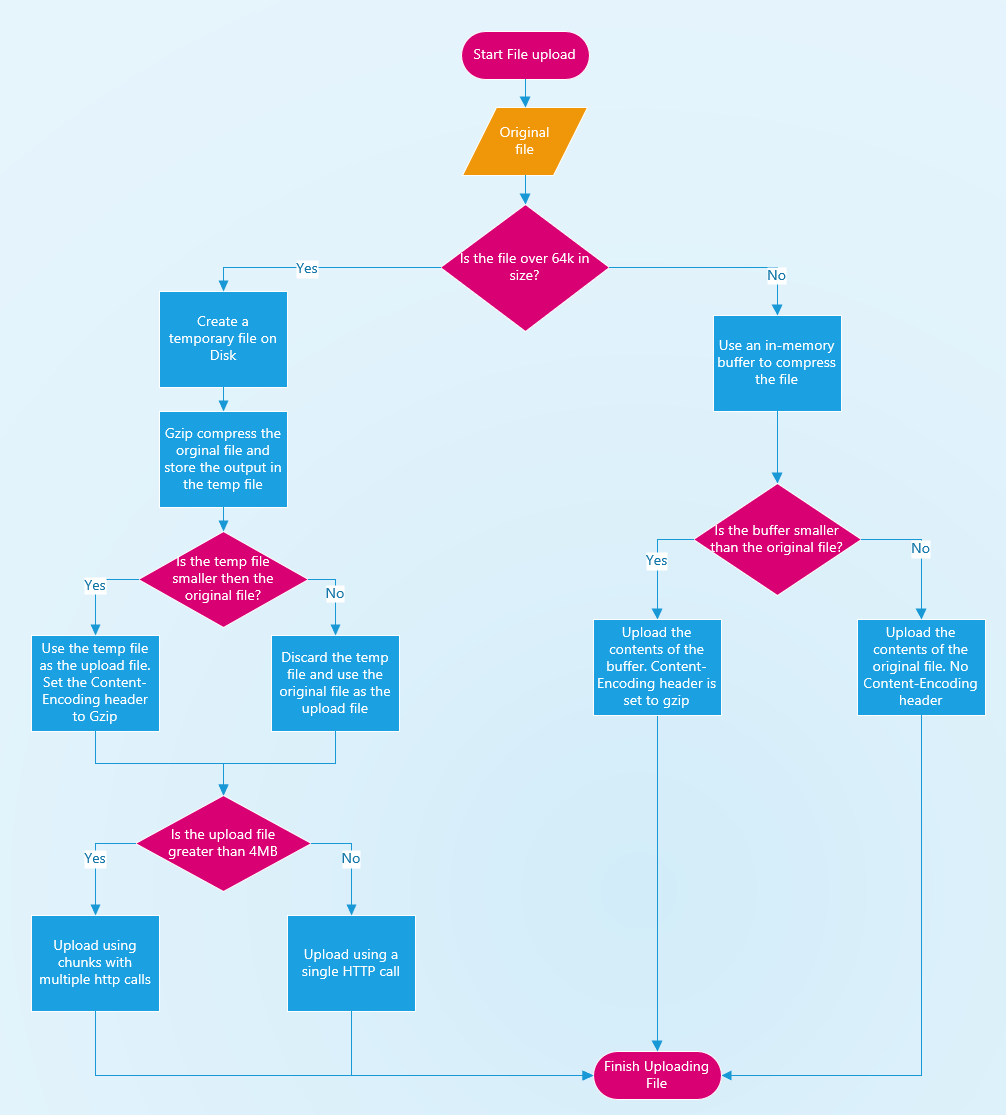
|
|
|
|
## Retry Logic when downloading an individual file
|
|
|
|

|
|
|
|
## Proxy support
|
|
|
|
This package uses the `@actions/http-client` NPM package internally which supports proxied requests out of the box.
|
|
|
|
## HttpManager
|
|
|
|
### `keep-alive` header
|
|
|
|
When an HTTP call is made to upload or download an individual file, the server will close the HTTP connection after the upload/download is complete and respond with a header indicating `Connection: close`.
|
|
|
|
[HTTP closed connection header information](https://tools.ietf.org/html/rfc2616#section-14.10)
|
|
|
|
TCP connections are sometimes not immediately closed by the node client (Windows might hold on to the port for an extra period of time before actually releasing it for example) and a large amount of closed connections can cause port exhaustion before ports get released and are available again.
|
|
|
|
VMs hosted by GitHub Actions have 1024 available ports so uploading 1000+ files very quickly can cause port exhaustion if connections get closed immediately. This can start to cause strange undefined behavior and timeouts.
|
|
|
|
In order for connections to not close immediately, the `keep-alive` header is used to indicate to the server that the connection should stay open. If a `keep-alive` header is used, the connection needs to be disposed of by calling `dispose()` in the `HttpClient`.
|
|
|
|
[`keep-alive` header information](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Keep-Alive)
|
|
[@actions/http-client client disposal](https://github.com/actions/http-client/blob/04e5ad73cd3fd1f5610a32116b0759eddf6570d2/index.ts#L292)
|
|
|
|
|
|
### Multiple HTTP clients
|
|
|
|
During an artifact upload or download, files are concurrently uploaded or downloaded using `async/await`. When an error or retry is encountered, the `HttpClient` that made a call is disposed of and a new one is created. If a single `HttpClient` was used for all HTTP calls and it had to be disposed, it could inadvertently effect any other calls that could be concurrently happening.
|
|
|
|
Any other concurrent uploads or downloads should be left untouched. Because of this, each concurrent upload or download gets its own `HttpClient`. The `http-manager` is used to manage all available clients and each concurrent upload or download maintains a `httpClientIndex` that keep track of which client should be used (and potentially disposed and recycled if necessary)
|
|
|
|
### Potential resource leaks
|
|
|
|
When an HTTP response is received, it consists of two parts
|
|
- `message`
|
|
- `body`
|
|
|
|
The `message` contains information such as the response code and header information and it is available immediately. The body however is not available immediately and it can be read by calling `await response.readBody()`.
|
|
|
|
TCP connections consist of an input and output buffer to manage what is sent and received across a connection. If the body is not read (even if its contents are not needed) the buffers can stay in use even after `dispose()` gets called on the `HttpClient`. The buffers get released automatically after a certain period of time, but in order for them to be explicitly cleared, `readBody()` is always called.
|
|
|
|
### Non Concurrent calls
|
|
|
|
Both `upload-http-client` and `download-http-client` do not instantiate or create any HTTP clients (the `HttpManager` has that responsibility). If an HTTP call has to be made that does not require the `keep-alive` header (such as when calling `listArtifacts` or `patchArtifactSize`), the first `HttpClient` in the `HttpManager` is used. The number of available clients is equal to the upload or download concurrency and there will always be at least one available.
|